MyAnimeList Web Scraper
Personal Web scraping project (Unguided) to extract anime and manga data.
PythonPandasBeautiful SoupRequestsWeb Scraping
Personal Project
Project Purpose
This project search for extract, structure, and analyze web data at scale. By scraping MyAnimeList (a top anime and manga database), it transforms unstructured website content into actionable datasets, showcasing skills in automation, problem-solving, and data pipeline creation.
Why MyAnimeList?
- Rich Data Source:
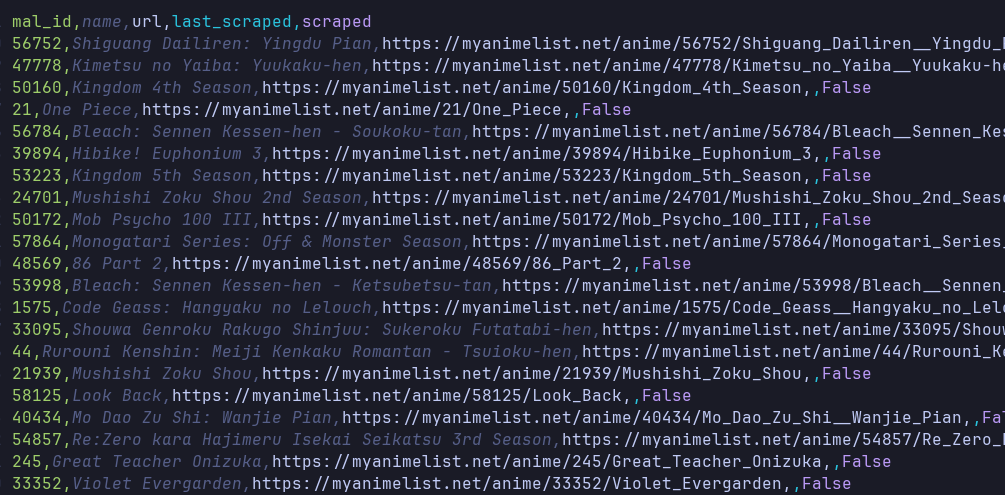
MyAnimeList is the largest anime database globally, with:- 20,000+ anime and manga entries
- User ratings, rankings, genres, and metadata
- Seasonal popularity trends
- Real-World Relevance:
This data powers:- Market analysis for streaming platforms (e.g., Crunchyroll, Netflix)
- Recommendation engine training
- Content licensing decisions
Core Skills Highlighted
Technical
- Web scraping (Beautiful Soup, Requests)
- Data pipeline design (raw → CSV transformation)
- Modern Python practices (Pathlib, type hints)
- Developer workflow optimization (UV, Ruff)
Strategic
- Balancing speed vs. website respect (ethics-first scraping)
- Prioritizing maintainability over quick fixes
- Translating business needs into technical specs
Business Value
Scraped data enables:
| Use Case | Impact Example |
|---|---|
| Competitor Analysis | Identify trending genres for content acquisition |
| Audience Insights | Analyze score vs. popularity correlations |
| Catalog Enrichment | Auto-generate metadata for media libraries |
| Price Benchmarking | Compare premium vs. free-tier anime performance |
Key Challenges & Solutions
| Challenge | Solution | Skill Demonstrated |
|---|---|---|
| Anti-Scraping Measures | Randomized delays + browser-like headers | Reverse-engineering web protections |
| Data Consistency | Robust HTML parsing with fallback logic | Handling unstructured data |
| Scalability | Modular code design (scraper/storage split) | System architecture planning |
| Maintenance | Type hints + modern Python practices | Future-proofing codebases |
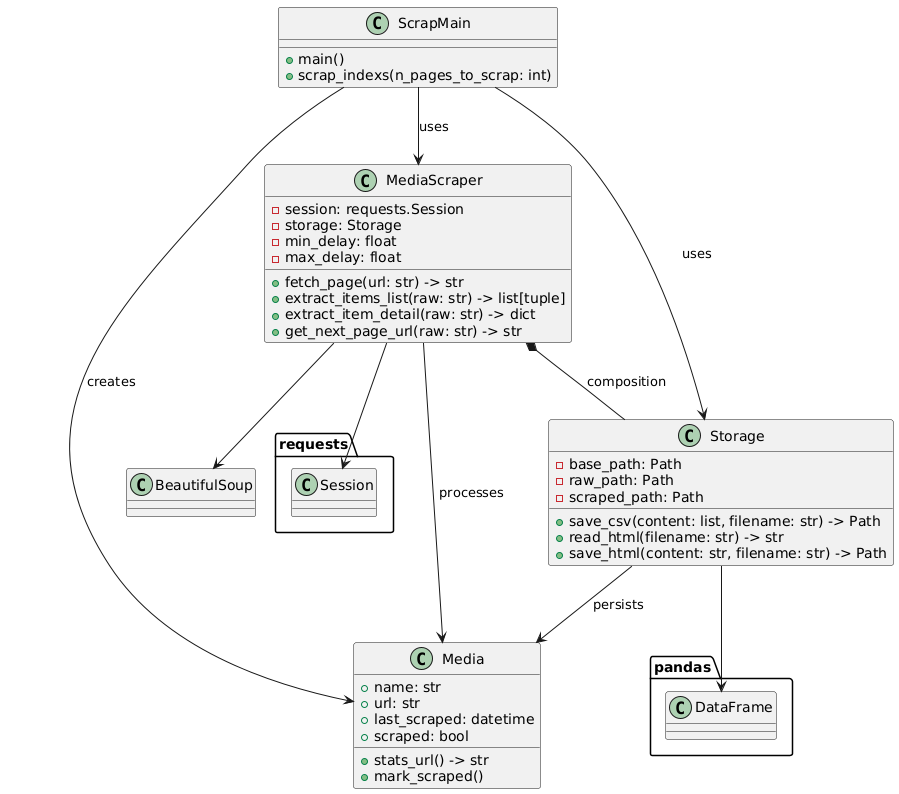
How it work
Core Tools & Libraries
Tech stack
Development Essentials
- UV: Blazing-fast Python package installer and resolver (alternative to
pip/pip-tools) - Ruff: Rust-powered linter for immediate feedback and code consistency
- Pathlib: Modern object-oriented file system paths (replaces legacy
os.path) - Rich: Beautiful terminal formatting for progress tracking and debugging
Web Scraping
- Beautiful Soup 4: HTML/XML parsing library for extracting structured data
- Requests: HTTP client with session persistence and header customization
- Pandas: Data manipulation library for CSV export functionality
Modern Python Features
- Type hints (
list[dict],str | Path) - Structural pattern matching (planned for future enhancements)
- F-strings and context managers
Key Technical Choices
Developer Experience
- UV Package Manager:
Replaced traditionalpipwith Astral’s UV for 10-100x faster dependency resolution
uv pip install -r requirements.txt- Ruff Linter:
Configured with strict rules for:
- Auto-fixable violations (PEP 8)
- Potential bug detection
- Type checking awareness
File Handling
from pathlib import Path # Modern path handling
self.raw_path = Path(base_path) / "data" / "raw" # Type-safe concatenationAnti-detection Measures
# Browser-like headers with randomized delays
self.session.headers.update({...})
delay = random.uniform(self.min_delay, self.max_delay)Project Structure (Simplified)
.
├── data/
│ ├── raw/ # HTML snapshots
│ └── scraped/ # Processed CSV files
├── src/
│ ├── scrap.py # Main workflow
│ ├── scraper.py # Core scraping logic
│ ├── models.py # Data clases of scraped items
│ └── storage.py # File I/O operations
├── pyproject.toml # Modern config format
└── requirements.txt # UV-compatible dependenciesFuture Technical Enhancements
- Implement Playwright for JavaScript-rendered content
- Add Pydantic models for data validation
- Introduce async HTTP client (HTTPX/httpx)
- Pre-commit hooks with Ruff and Mypy
- Docker containerization for reproducibility
git clone https://github.com/kkyouma/myanimelist_scraper.git
cd myanimelist_scraper